YOLO(You Only Look Once)是一种流行的实时目标检测算法,它将目标检测任务作为一个回归问题来处理,直接预测图像中所有目标的位置和类别。与传统的目标检测方法(例如 R-CNN 系列)不同,YOLO 通过一个单一的神经网络在一次前向传播中同时进行目标识别和定位,因此非常高效,能够在实时应用中使用。
YOLO v11 环境配置
参考教程:
YOLO环境配置
Anaconda的安装与环境设置
CUDA、Pytorch、Pycharm的安装与配置
我的操作环境
环境:Win11专业版24H2版本
CPU GPU:i7 14650HX + RTX4060 Laptop
Driver Version: 566.14 CUDA Version:12.7
Conda创建虚拟环境
采用Anaconda管理,使用Conda创建虚拟环境。类似Docker,感觉相比Docker更容易上手。
首先下载了Anaconda 2024-6-1版本,内置Conda版本为25.
Conda创建了虚拟环境。名为yolo_env
首先创建并激活虚拟环境。在Anaconda Navagator中操作即可。
虚拟环境中Pytorch的安装
Pytorch的安装:https://pytorch.org/get-started/locally/
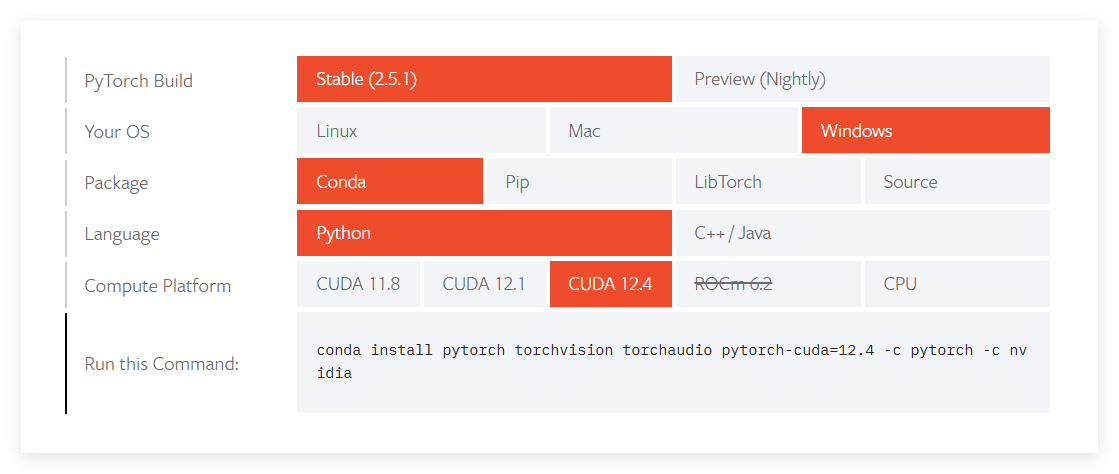
选择如上的版本号。在Pycharm终端中输入即可在对于环境中安装。
CUDA安装-不是安装在虚拟环境
首先安装CUDA toolkit
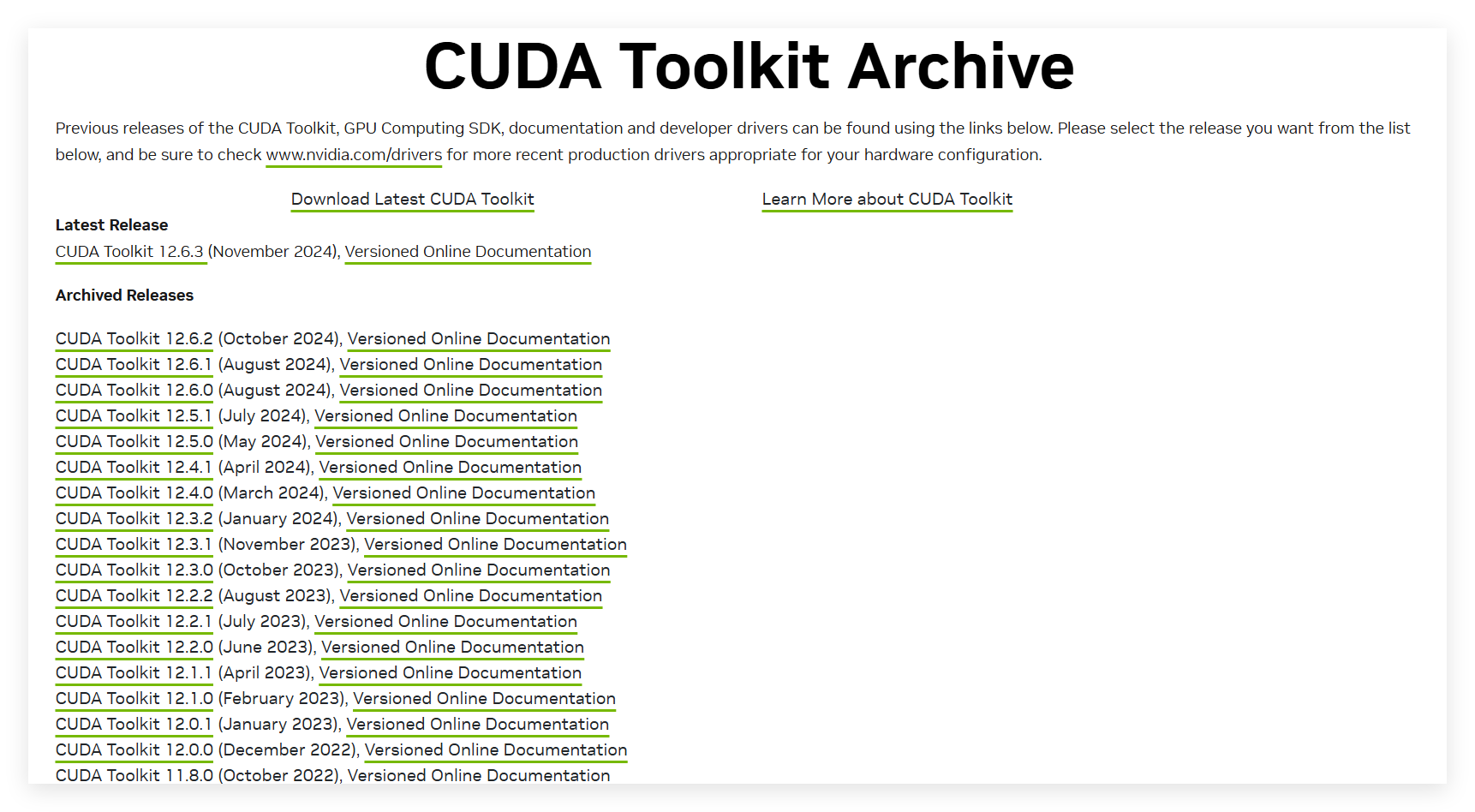
这里我选了12.4 与Pytorch对应起来。
PS:cuda安装
安装cuda时,第一次会让设置临时解压目录,第二次会让设置安装目录;
临时解压路径,建议默认即可,也可以自定义。安装结束后,临时解压文件夹会自动删除;
安装目录,建议默认即可;
注意:临时解压目录千万不要和cuda的安装路径设置成一样的,否则安装结束,会找不到安装目录的!!!
选择自定义安装
安装完成后,配置cuda的环境变量;
命令行中,测试是否安装成功;
双击“exe文件”,选择下载路径(推荐默认路径)
之后选择自定义安装,精简版本是下载好所有组件,并且会覆盖原有驱动,所以在这里推荐自定义下载
网上都建议将Visual Studio Integration选项取消(在CUDA选项下),其没什么用而且会影响下载
确定安装路径(可以修改,最好记住)
注意事项:取消勾选Visual Studio Integration(这里解释一下,这个模块是对VS编译的支持,没有安装VS无法征常工作,而需要VS辅助则是需要编译cuda程序,这种编译不建议在Windows下进行,一般Windows下能跑深度学习原生框架的代码就行),其余全部勾选。
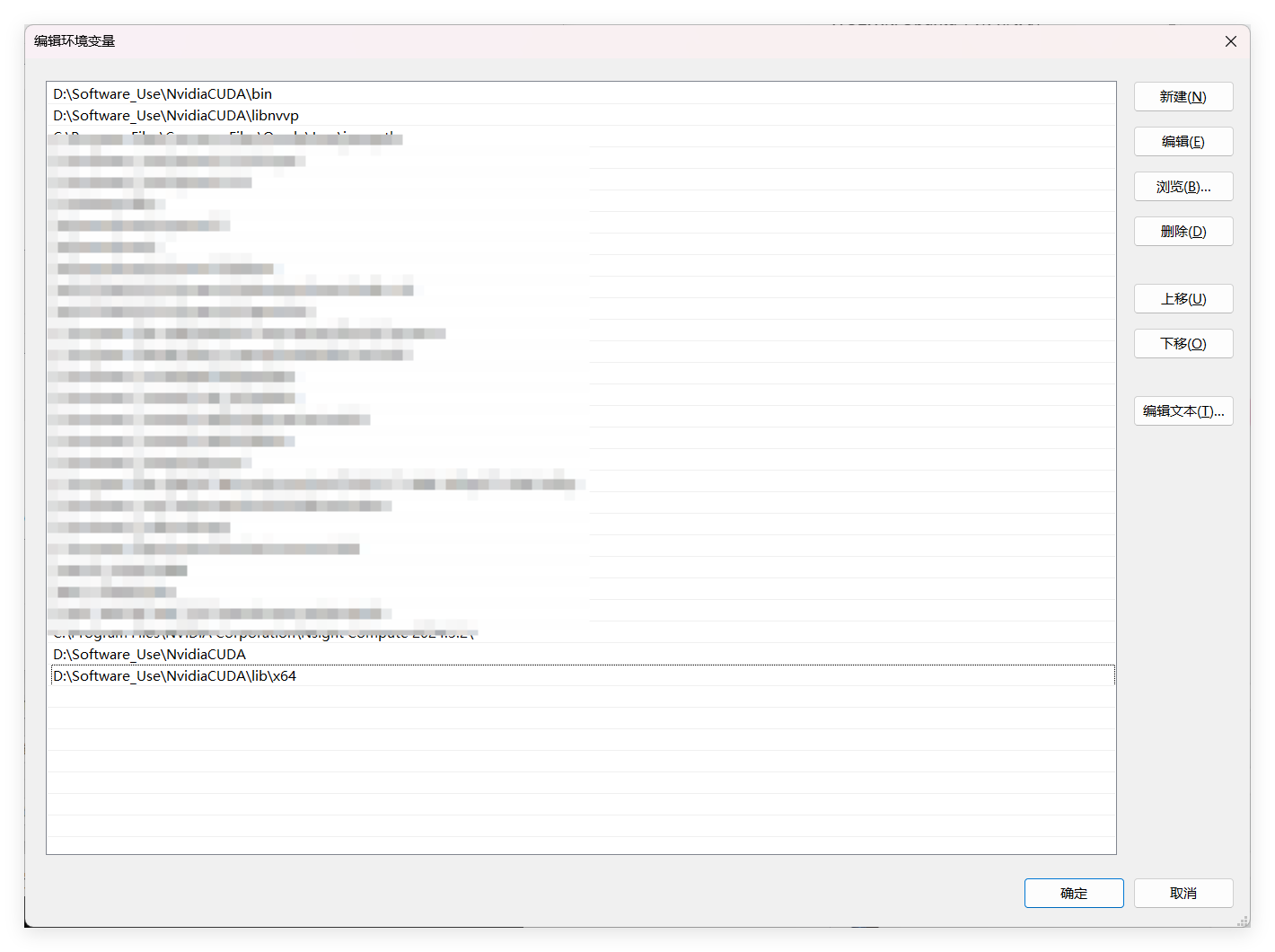
安装完成后查看一下是否有环境变量,没有自己手动添加(9.0之后的版本环境变量是自动配置的,无需添加)
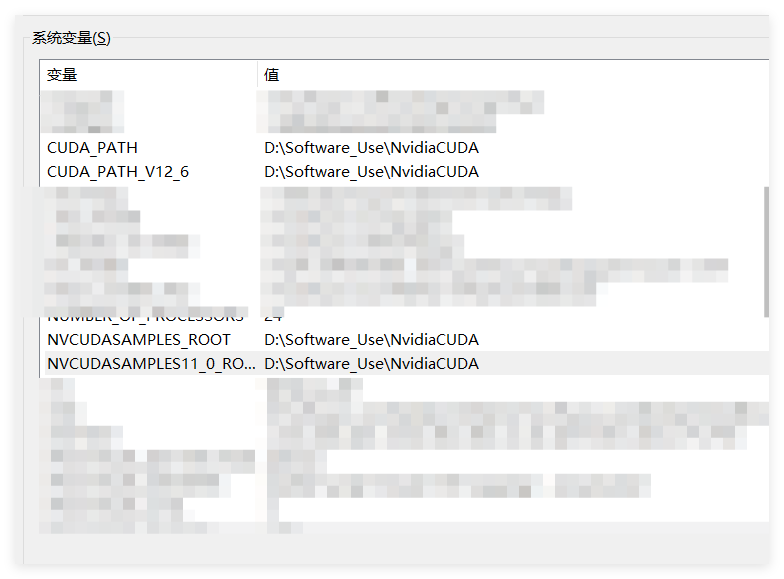
一共需要4个环境变量,网上说只自动生成了前两个,再手动添加一下上图中下面那两个。
卸载CUDA
参考:https://www.jianshu.com/p/c184e270b8d4
保留如下的红色框选 删除其他的 删除顺序任意
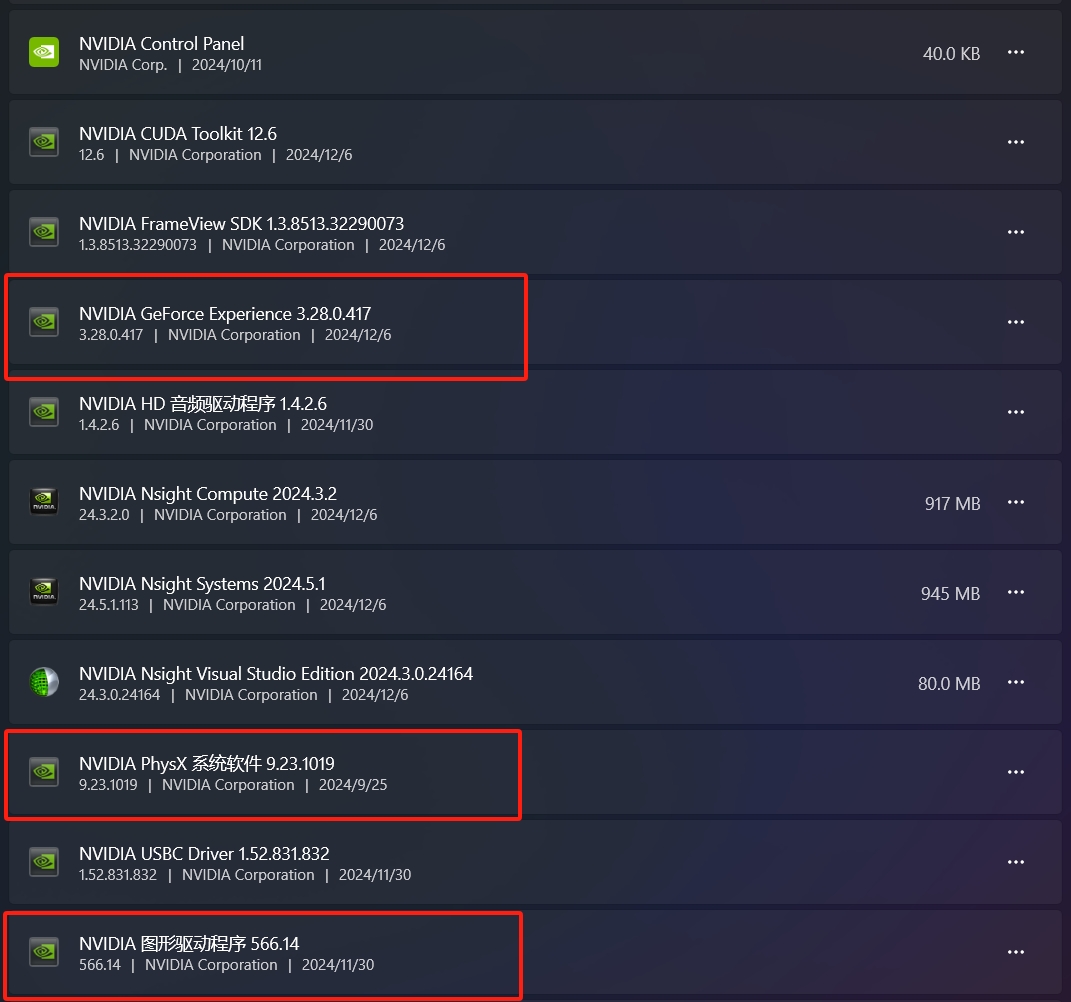
把Nsight CUDA toolkit删除了 先不删除了 其他的和这个古老教程对应不起来
还是使用Docker配置简单一些,但是不知道Docker能否配置CUDA?或者Nvidia有专门的Docker仓库。?
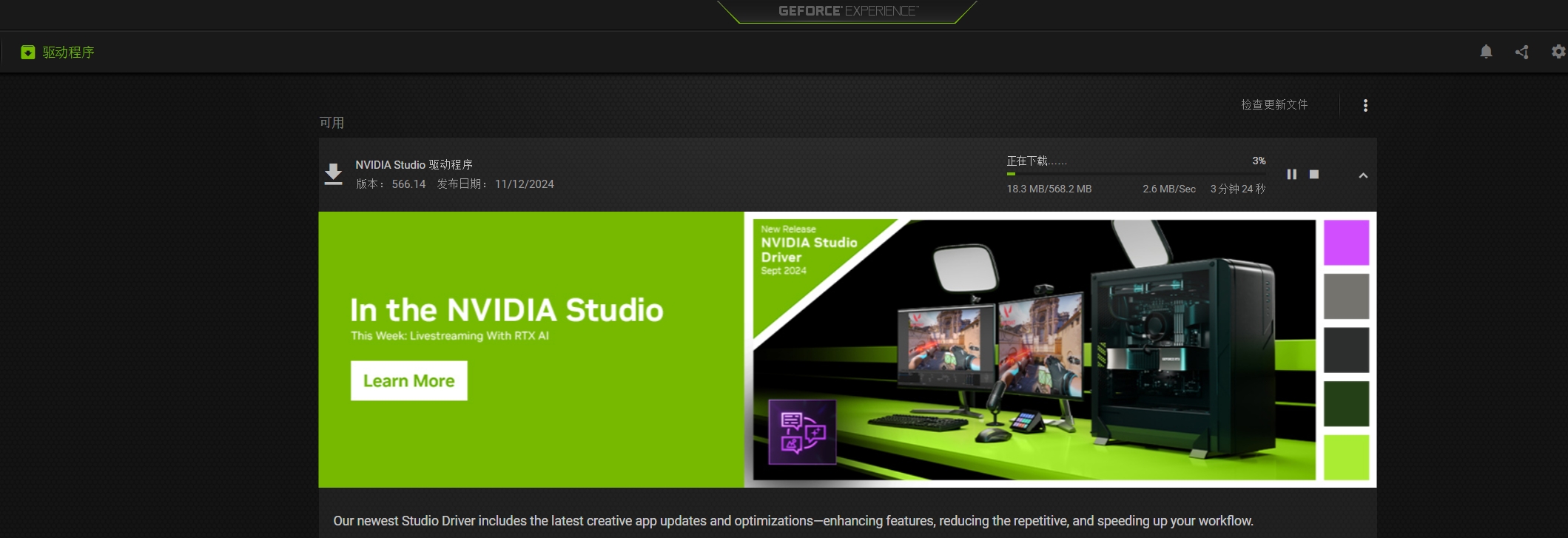
再次安装CUDA时发现CUDA安装失败。
在网上查资料发现是驱动错误导致的,之前我是GameReady驱动,现在换成Studio系列。在这个驱动管理软件下能直接更换。
CUDNN安装
cuDNN 其实就是 CUDA 的一个补丁而已,专为深度学习运算进行优化的。然后再参加环境变量
下载后发现其实cudnn不是一个exe文件,而是一个压缩包,解压后,有三个文件夹,把三个文件夹拷贝到cuda的安装目录下。
拷贝时看到,CUDA 的安装目录中,有和 cuDNN 解压缩后的同名文件夹,这里注意,不需要担心,直接复制即可。cuDNN 解压缩后的同名文件夹中的配置文件会添加到 CUDA安装目录中的同名文件夹中。【此处还是建议还是分别把文件夹的内容复制到对应文件夹中去】
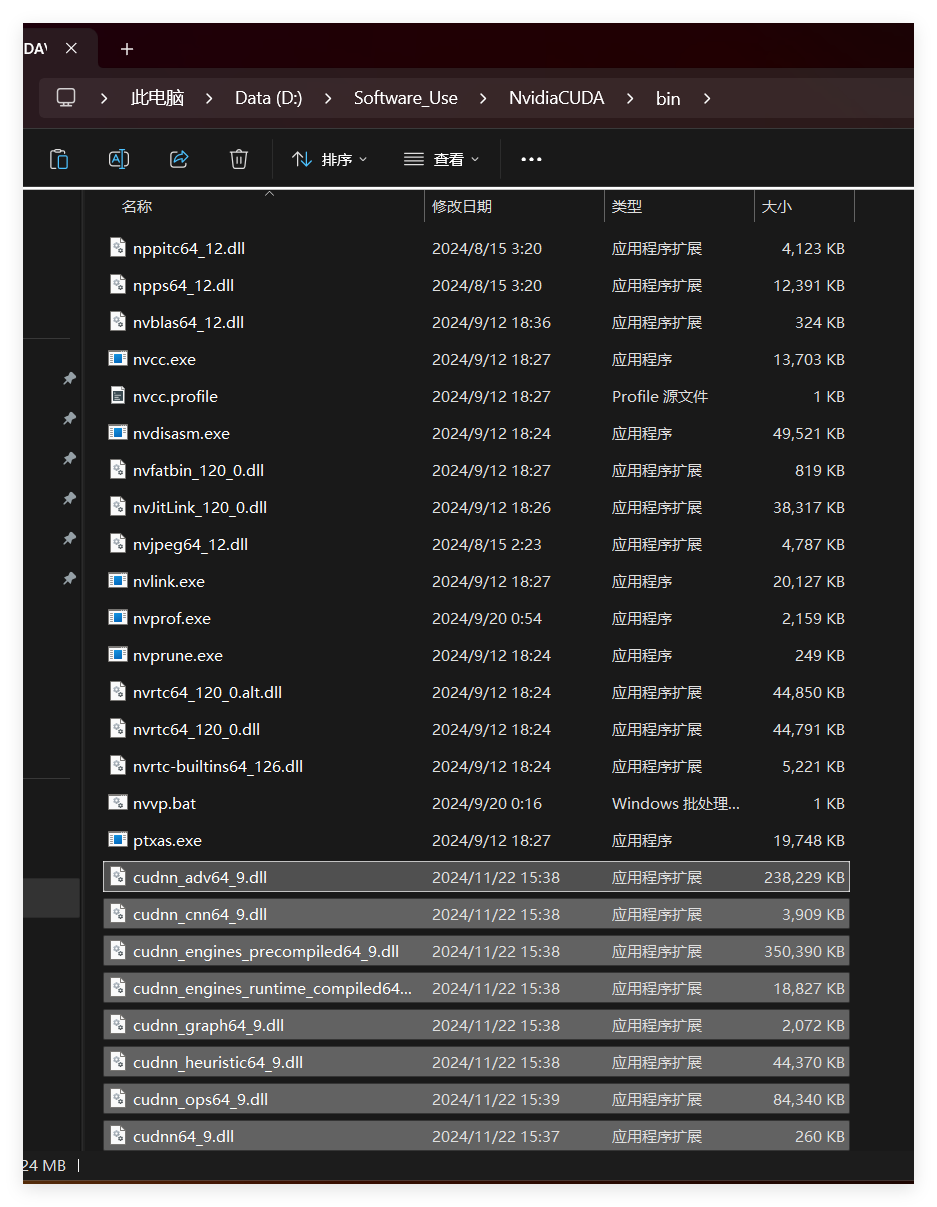
在系统变量-Paht中添加环境变量
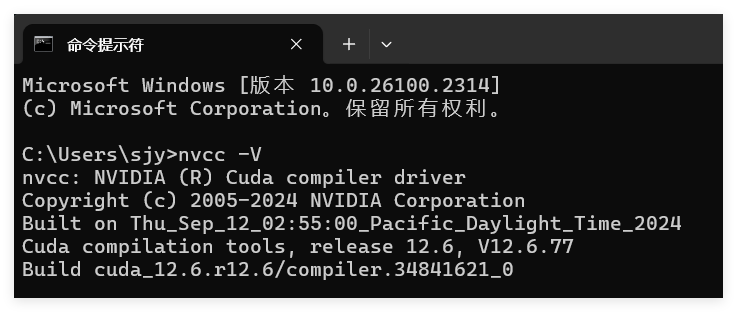
如何测试环境是否安装成功?
打开cmd,输入nvcc -V查看cuda版本
使用Torch验证CUDA是否可用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# yolo detect train data=data/data.yaml model=yolo11n.pt epochs=10 batch=4 imgsz=640 device=0
import torch
# 检查 CUDA 是否可用
print(f"CUDA available: {torch.cuda.is_available()}")
# 如果 CUDA 可用,打印当前设备名称
if torch.cuda.is_available():
print(f"Current device: {torch.cuda.get_device_name(0)}")
# 获取 CUDA 版本
cuda_version = torch.version.cuda
print(f"CUDA Version: {cuda_version}")
# 获取 cuDNN 版本
cudnn_version = torch.backends.cudnn.version()
print(f"cuDNN Version: {cudnn_version}")
|
不可用的运行结果
1
2
3
|
CUDA available: False
CUDA Version: None
cuDNN Version: None
|
可用的运行结果
1
2
3
|
CUDA available: False
CUDA Version: None
cuDNN Version: None
|
torch安装
pip install torch即可
Torch 和 PyTorch 是两个不同的深度学习框架。
1、Torch 是一个用 Lua 编程语言编写的深度学习框架,而 PyTorch 是一个用 Python 编程语言编写的深度学习框架。
2、Torch 是由 Facebook 的研究团队开发的,而 PyTorch 是由 Facebook AI Research(FAIR)团队开发的。
3、PyTorch 的设计更加灵活和易于使用,提供了更多高级接口和功能,使得用户可以更方便地构建、训练和部署深度学习模型。
4、Torch 在一些方面比 PyTorch 更早成为流行的深度学习框架,但 PyTorch 在近年来逐渐取代了 Torch,成为了研究和工业界广泛使用的深度学习框架之一。
Pycharm配置虚拟环境
下一步准备使用Pycharm进行开发。感觉相比Vscode好配置很多。
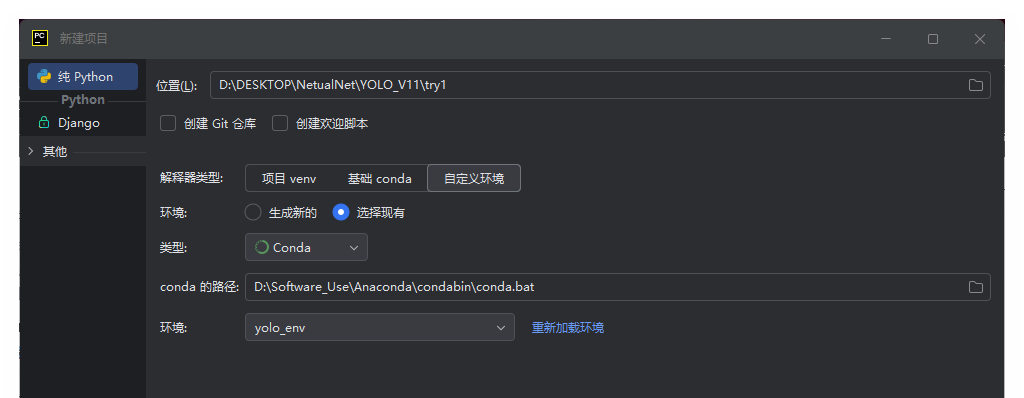
在Pycharm中新建项目,选择之前创建的虚拟环境。
后在这个虚拟环境中安装Pytorch。
YOLO 架构与原理
ultralytics发布了最新的作品YOLOv11,这一次YOLOv11的变化相对于ultralytics公司的上一代作品YOLOv8变化不是很大的(YOLOv9、YOLOv10均不是ultralytics公司作品),其中改变的位置涉及到C2f变为C3K2,在SPPF后面加了一层类似于注意力机制的C2PSA,还有一个变化大家从yaml文件是看不出来的就是它的检测头内部替换了两个DWConv,以及模型的深度和宽度参数进行了大幅度调整,但是在损失函数方面就没有变化还是采用的CIoU作为边界框回归损失。
YOLO v11 Demo
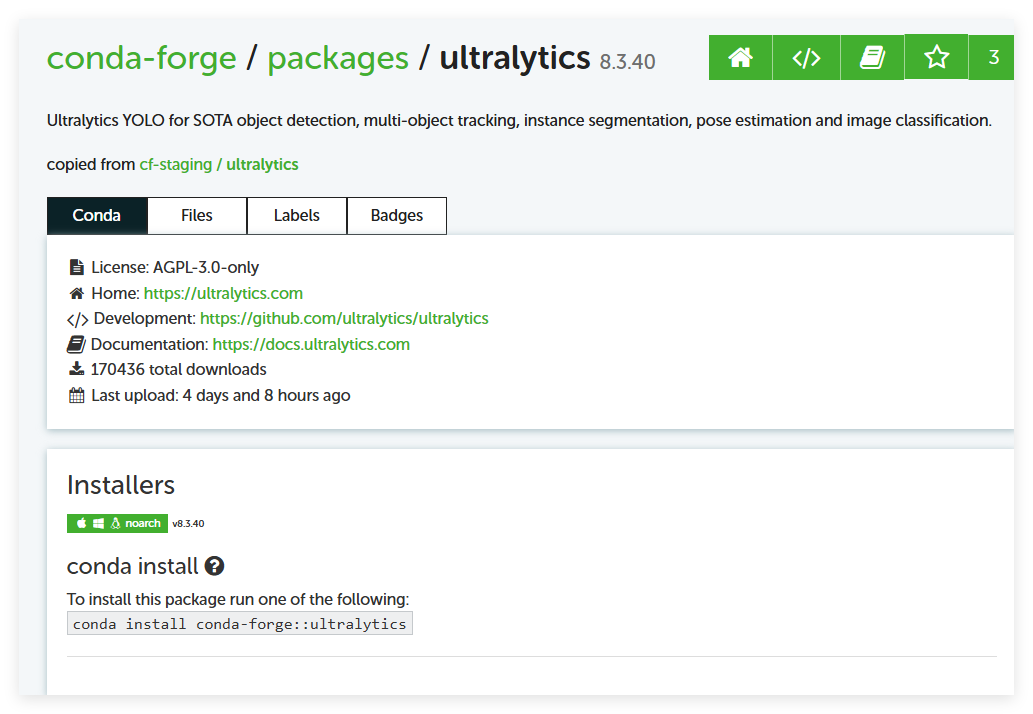
安装ultralytics。运行时提示缺少package的错误就是没安装这个。
按照官方教程使用Conda安装即可 如下图
1
|
conda install conda-forge::ultralytics
|
YOLO Example:
1
2
3
4
|
from ultralytics import YOLO
model=YOLO("yolo11n.pt")
results=model("H:\Computer Vision\yolov11\pra\pra1\ice_skating.mp4",save=True,show=True)
|
参考YOLO官方仓库,安装ultralytics:https://github.com/ultralytics/ultralytics
Python中引用地址可能存在转义错误,在地址前加r即可。即保持字符原始值的意思。
如r"H:\Computer Vision\yolov11\pra\pra1\ice_skating.mp4"
PS 也可以替换为双反斜杠,替换为正斜杠。
自己训练数据并完成任务-打僵尸为例子
参考教程:yolo 锁头 教程
数据集获取
首先下载一个植物大战僵尸经典版本。这个属实是难倒我了。。。最后在植物大战僵尸吧找到了资源,并下载了完美存档。
下一步就是先自己玩一把,然后录屏,截图出300张左右的数据集。
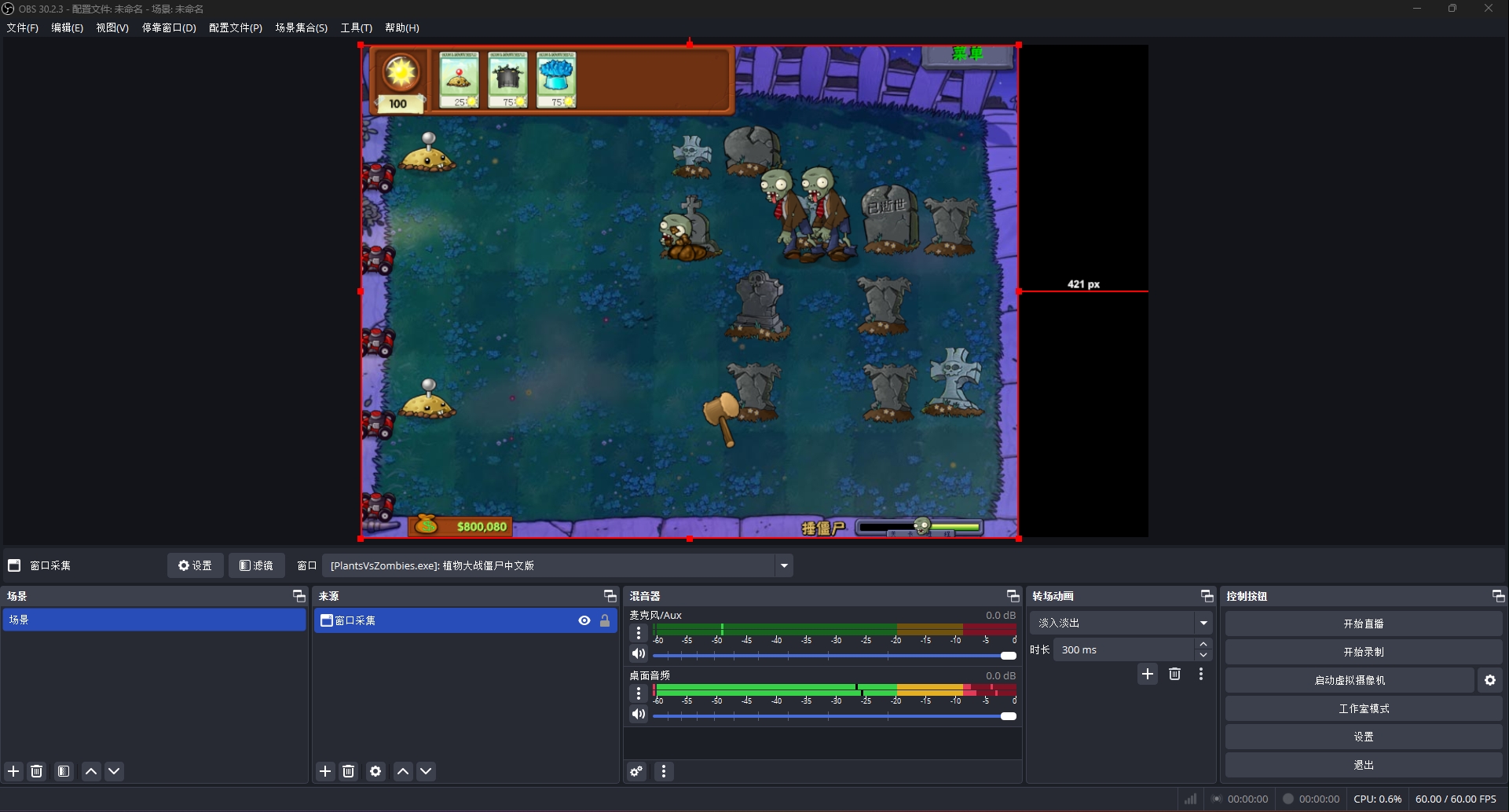
数据标注
先使用教学视频中UP给出的数据集压缩包进行自己的训练,后续有时间再试试自己标注数据集。
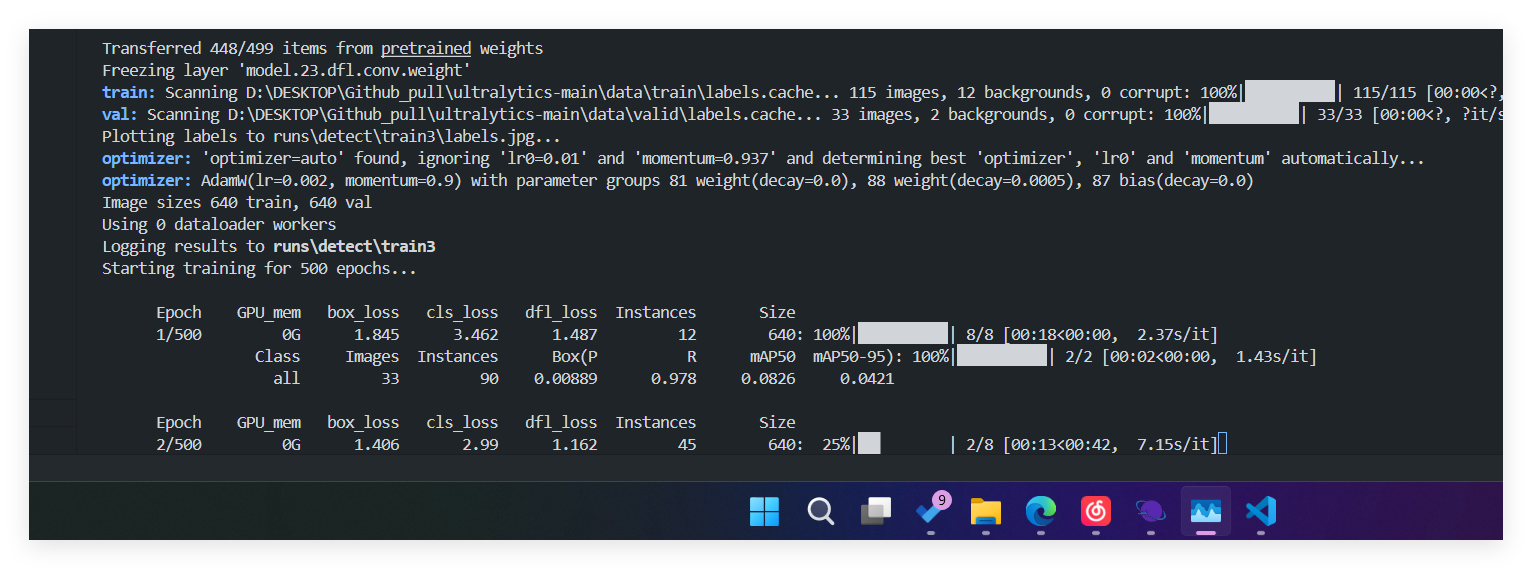
训练数据
设置训练了500次 实际训练了200+次数
运行程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
from ultralytics import YOLO #导入
import pyautogui as pt # 控制鼠标点击的一个Python库
import pygetwindow # 导入pygetwindow库,用于获取窗口信息
import numpy as np # 导入numpy库,用于数组和矩阵操作
import cv2 as cv # 导入OpenCV库,用于图像处理
import torch # 导入PyTorch库,用于深度学习操作
from PIL import ImageGrab # 从Pillow库中导入ImageGrab,用于屏幕截图
model = YOLO("best.pt") # 加载YOLO模型,使用训练好的"best.pt"权重文件
window_title = "植物大战僵尸中文版" # 设置目标窗口标题为“植物大战僵尸中文版”
window = pygetwindow.getWindowsWithTitle(window_title)[0] # 获取该窗口的窗口对象
device = torch.device("cuda:0") # 设置设备为GPU(CUDA),确保YOLO模型在GPU上运行
model.to(device) # 将模型加载到GPU上
while True:
if window: # 检查目标窗口是否存在
x, y, w, h = window.left, window.top, window.width, window.height # 获取窗口的位置信息和大小
screenshot = ImageGrab.grab(bbox=[x, y, x + w, y + h]) # 对窗口进行截图
image_src = cv.cvtColor(np.array(screenshot), cv.COLOR_RGB2BGR) # 将截图转换为OpenCV支持的BGR格式
size_x, size_y = image_src.shape[1], image_src.shape[0] # 获取截图的宽度和高度
image_det = cv.resize(image_src, (640, 640)) # 将截图调整为YOLO模型需要的输入大小(640x640)
result = model.predict(source=image_det, imgsz=640, conf=0.7, save=False) # 使用YOLO模型进行目标检测
boxes = result[0].boxes.xywhn # 获取检测框的中心点和宽高(归一化坐标)
boxes = sorted(boxes, key=lambda x:x[0]) # 按检测框的x坐标从左到右排序
count = 0 # 初始化计数器,用于限制点击次数
for box in boxes: # 遍历每个检测框 # 在截图中绘制检测框
cv.rectangle(image_src, (int((box[0] - box[2]/2) * size_x), int((box[1] - box[3]/2) * size_y)),
(int((box[0] + box[2]/2) * size_x), int((box[1] + box[3]/2) * size_y)),
color=(255, 255, 0), thickness=2)
pt.click(x=x + box[0] * size_x, y=y + box[1] * size_y) # 模拟鼠标点击检测框中心
count += 1
if count > 4: # 如果点击次数超过4次,退出循环
break
cv.imshow("frame", image_src) # 显示实时处理后的图像,窗口名称为“frame”
if cv.waitKey(1) == ord('q'): # 检测键盘按键,如果按下‘q’,退出程序
break
pass
|
僵尸水族馆
实现自动收集阳光,自动购买僵尸,自动喂食僵尸三个功能。
数据集制作
OBS录屏,使用Python中的CV库进行处理,截图120张左右。人工筛选出带有阳光的100张左右图片。
以下是,使用Python对视频进行截图的程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
import cv2
import os
# 设置视频文件路径
video_path = 'textttt.mp4'
output_folder = 'raw_picture'
# 创建输出文件夹,如果不存在的话
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 打开视频文件
cap = cv2.VideoCapture(video_path)
# 获取视频的帧率(FPS)
fps = cap.get(cv2.CAP_PROP_FPS)
# 获取视频的总帧数
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
# 循环读取视频帧
for frame_num in range(0, frame_count, int(fps)): # 每秒截图一次
cap.set(cv2.CAP_PROP_POS_FRAMES, frame_num) # 设置当前帧的位置
ret, frame = cap.read() # 读取当前帧
if ret:
# 保存帧为图片
frame_filename = os.path.join(output_folder, f'frame_{frame_num}.jpg')
cv2.imwrite(frame_filename, frame)
else:
break
# 释放视频文件
cap.release()
print(f"已完成截图,截图保存在 '{output_folder}' 文件夹中。")
|
之后使用RoboFlow平台进行在线标注。
RoboFlow平台数据集标注
上传图片到RoboFlow平台,选择人工标注。这里可以选自动标注与平台帮你。这里我们选自己标注。
图片总数100.这里可以团队分工。
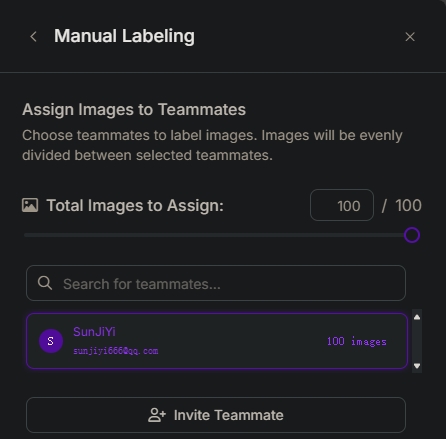
在线标注平台
标注完成后,选择分别用于训练,验证,以及测试的比例。
训练即训练模型用的图片,验证则为在训练中验证的图片。以反馈训练效果。测试即训练完成后的测试。
这里选择常用比例7:2:1
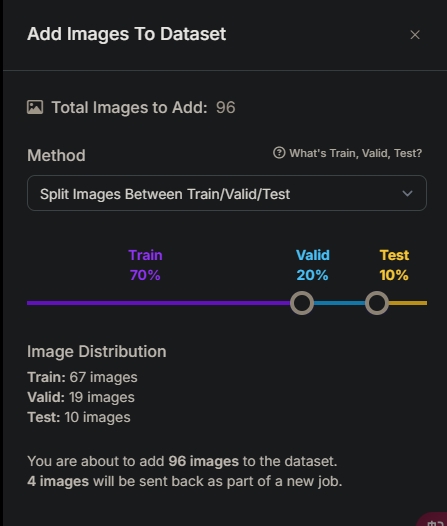
最终如下,有4张图片没有标注,也就是图片中没有目标。
本地训练
训练同上

运行程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
from ultralytics import YOLO # 导入YOLO模型
import pyautogui as pt # 控制鼠标点击的Python库
import pygetwindow # 导入pygetwindow库,用于获取窗口信息
import numpy as np # 导入numpy库,用于数组和矩阵操作
import cv2 as cv # 导入OpenCV库,用于图像处理
import torch # 导入PyTorch库,用于深度学习操作
from PIL import ImageGrab # 从Pillow库中导入ImageGrab,用于屏幕截图
import time # 导入time库,用于控制点击间隔
# 加载YOLO模型
model = YOLO("best.pt") # 加载训练好的模型权重文件
# 设置目标窗口标题
window_title = "植物大战僵尸中文版"
window = pygetwindow.getWindowsWithTitle(window_title)[0] # 获取窗口对象
# 设置设备为GPU
device = torch.device("cuda:0")
model.to(device) # 将模型加载到GPU上
# 设置点击目标的坐标
buy_zombie_position = (window.left + 110, window.top + 70) # 右上角位置
feed_zombie_position1 = (window.left + window.width // 2, window.top + window.height // 2 -100) # 中间空白区域
feed_zombie_position2 = (window.left + window.width // 2 - 100, window.top + window.height // 2-100) # 中间空白区域
feed_zombie_position3 = (window.left + window.width // 2 + 100, window.top + window.height // 2-100) # 中间空白区域
feed_zombie_position4 = (window.left + window.width // 2 - 100, window.top + window.height // 2) # 中间空白区域
feed_zombie_position5 = (window.left + window.width // 2 + 100, window.top + window.height // 2) # 中间空白区域
# 控制点击间隔时间
click_interval = 1 # 每秒点击一次
while True:
if window: # 检查目标窗口是否存在
x, y, w, h = window.left, window.top, window.width, window.height # 获取窗口的位置信息和大小
screenshot = ImageGrab.grab(bbox=[x, y, x + w, y + h]) # 对窗口进行截图
image_src = cv.cvtColor(np.array(screenshot), cv.COLOR_RGB2BGR) # 转换为BGR格式
size_x, size_y = image_src.shape[1], image_src.shape[0] # 获取截图的宽度和高度
image_det = cv.resize(image_src, (640, 640)) # 调整为YOLO模型需要的输入大小
result = model.predict(source=image_det, imgsz=640, conf=0.7, save=False) # 使用YOLO模型进行目标检测
boxes = result[0].boxes.xywhn # 获取检测框
boxes = sorted(boxes, key=lambda x: x[0]) # 按x坐标排序
# 在右上角购买僵尸
# pt.click(buy_zombie_position) # 模拟点击右上角购买僵尸
# pt.click(feed_zombie_position1) # 模拟点击中间位置喂食僵尸
# pt.click(feed_zombie_position2) # 模拟点击中间位置喂食僵尸
# pt.click(feed_zombie_position3) # 模拟点击中间位置喂食僵尸
# pt.click(feed_zombie_position4) # 模拟点击中间位置喂食僵尸
# pt.click(feed_zombie_position5) # 模拟点击中间位置喂食僵尸
# 遍历每个检测框
count = 0
for box in boxes:
# 在截图中绘制检测框
cv.rectangle(image_src,
(int((box[0] - box[2]/2) * size_x), int((box[1] - box[3]/2) * size_y)),
(int((box[0] + box[2]/2) * size_x), int((box[1] + box[3]/2) * size_y)),
color=(255, 255, 0), thickness=2)
# 在检测框中心点击
pt.click(x=x + box[0] * size_x, y=y + box[1] * size_y)
count += 1
if count > 1: # 如果点击次数超过4次,退出循环
break
# 显示实时图像
cv.imshow("frame", image_src)
# 如果按下‘q’键,退出程序 不知道为什么 不起作用
if cv.waitKey(1) == ord('q'):
break
cv.destroyAllWindows() # 关闭OpenCV显示窗口
|